
Overview
Đối với hệ thống lưu trữ dữ liệu phân tán (Apache Cassandra, Amazon DynamoDB, Google Spanner,...), consistent hashing đóng vai trò siêu cấp vô địch thiên hạ giúp dữ liệu được chia đều cho các node. Thông qua bài viết này ta sẽ cùng tìm hiểu về consistent hashing, nó hoạt động ra sao và tại sao nó lại là 'xương sống' của hệ thống cloud hiện đại.
Trước hết ta sẽ tìm hiểu một vấn đề nhỏ hơn trước. Nhớ cái hồi đi phỏng vấn vô Galaxy FinX, mình được các anh yêu cầu
code lại HashMap, dù code hơi ngu mà được guide nên làm cũng tạm. Mình làm kiểu kiểu như này
class HashMap {
final int SIZE = 100;
int[] data;
HashMap() {
data = new int[100];
}
public int get(int key) { return data[key];}
public void set(int key, int value) {
int hashedKey = hash(key);
data[hashedKey] = value;
}
private int hash(int key) { return key % SIZE; }
}
Okay, bỏ qua những khía cạnh về null-safety, key collision thì vấn đề đặt ra là:
Đến khi data đã được điền hết 100 ô, muốn mở rộng thêm thì phải làm gì?
Một cách đơn giản nhất là ta sẽ tạo một cái HashMap mới, với SIZE to hơn, rồi tiến hành hash lại toàn bộ dữ liệu đã có
trong data cũ.
Đến đây, ta mở rộng bài toán trên thành bài toán to hơn trong hệ thống phân tán với mỗi ô dữ liệu là một server (một node) lưu trữ dữ liệu, bài toán đặt ra là làm thế nào để vừa chia đều dữ liệu cho các node, vừa phải làm thế nào để có thể dễ dàng thêm/bớt một node mà không phải lưu chia lại toàn bộ dữ liệu của tất các các node còn lại.
Câu trả lời là...
Consistent hashing
Consistent hashing là một kỹ thuật ánh xạ khoá (key) lên một vòng tròn (hash ring), sao cho khi số lượng node (máy chủ lưu trữ) thay đổi, chỉ một phần nhỏ dữ liệu cần được di chuyển lại. Cụ thể, trung bình chỉ khoảng k/n bản ghi phải thay đổi vị trí, với k là tổng số bản ghi và n là số node.
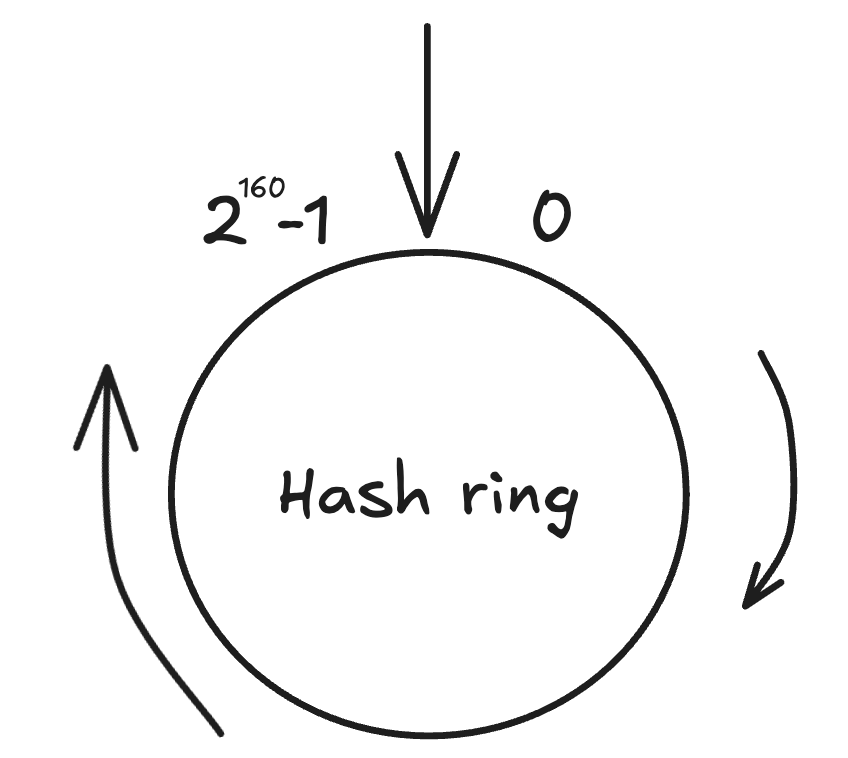
Hình 1: Hash ring với hàm băm SHA-1
Khi muốn xác định một khoá (key) sẽ được lưu ở node nào, ta băm khoá đó để lấy vị trí trên vòng và di chuyển theo chiều kim đồng hồ để tìm node đầu tiên nằm sau vị trí đó. Trong hệ thống lưu trữ phân tán, mỗi lần ghi dữ liệu mới, hệ thống sẽ tính toán vị trí của khoá trên vòng và chọn node tương ứng để lưu trữ.
Khi thêm mới node
Khi một node mới được thêm vào vòng, chỉ những dữ liệu nằm giữa node mới và node kế trước nó trên vòng cần được phân phối lại.
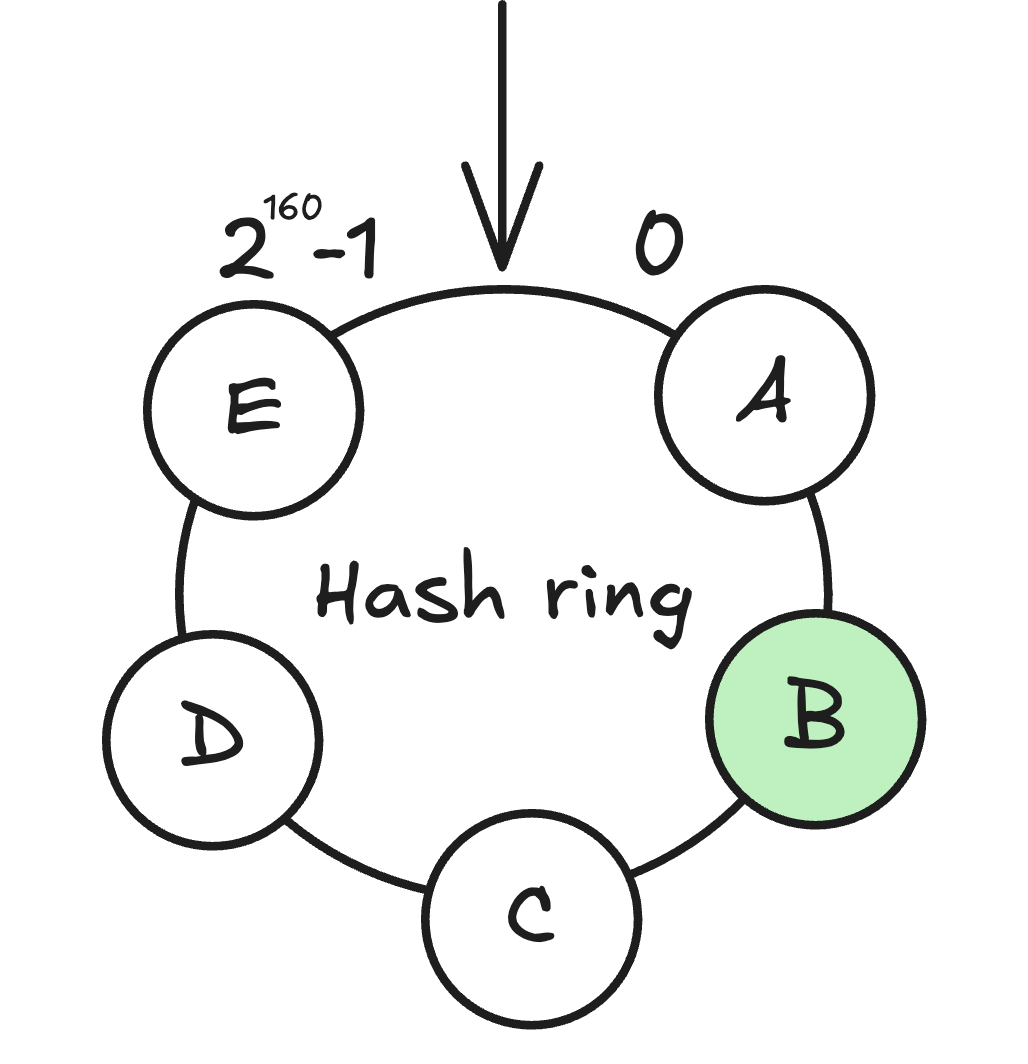
Hình 2: Thêm mới node A
Khi xoá node
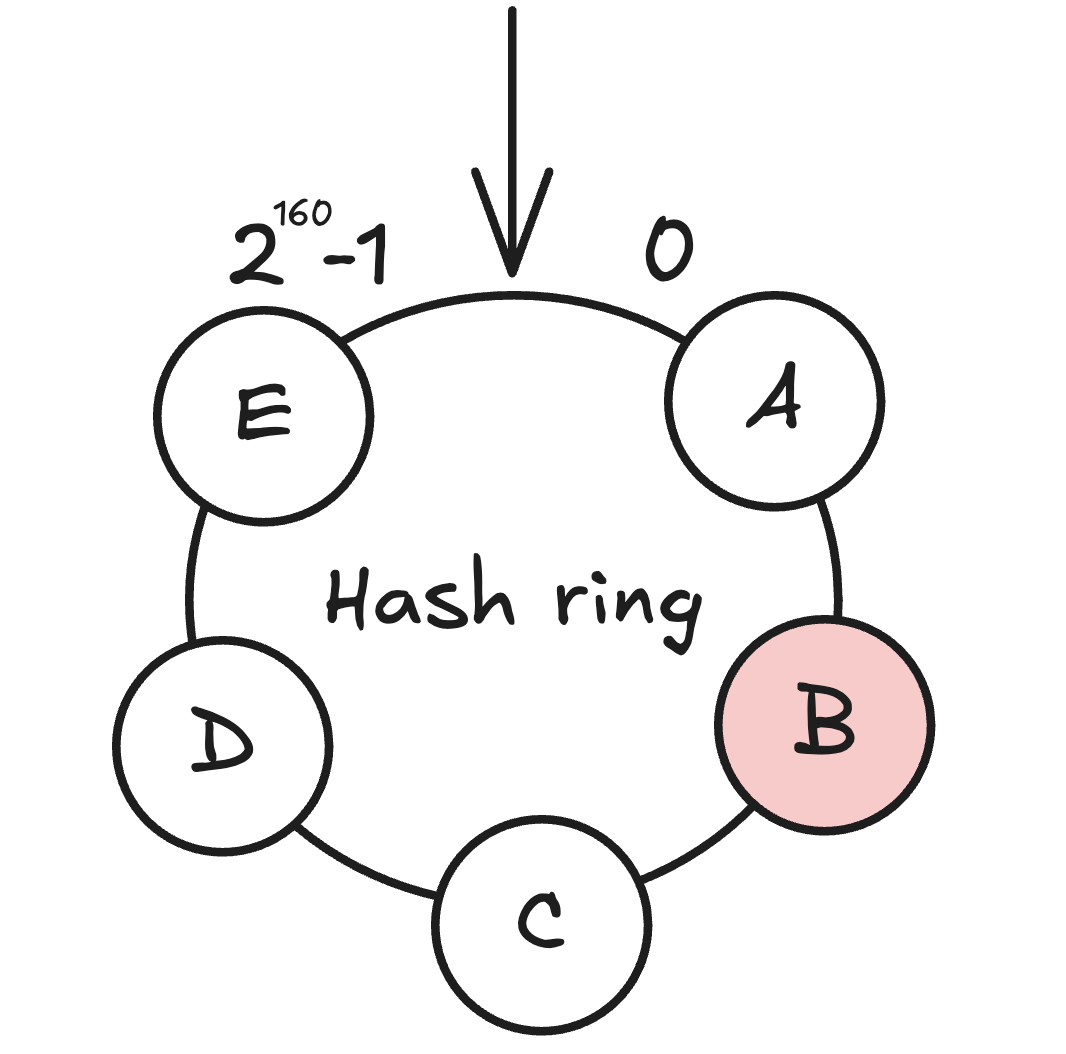
Hình 3: Xoá node B
Tương tự, khi một node bị xoá, chỉ những dữ liệu nằm giữa node bị xoá và node kế tiếp theo chiều kim đồng hồ cần được chuyển sang node mới.
Tuy nhiên, nhược điểm của cách này là node kế tiếp sẽ phải gánh toàn bộ dữ liệu của node vừa bị xoá, dẫn đến mất cân bằng tải.
Consistent hashing's variant - Virtual node
Để khắc phục vấn đề nêu trên, DynamoDB và nhiều hệ thống khác sử dụng virtual nodes: mỗi node vật lý sẽ được gán nhiều điểm (sau gọi là tokens) trên vòng thay vì một vị trí cố định. Điều này giúp:
- Phân phối dữ liệu đều hơn.
- Giảm rủi ro quá tải khi thêm hoặc xoá node.
- Hỗ trợ các node có cấu hình phần cứng khác nhau (node mạnh → nhiều virtual nodes).
Hình dưới đây biểu diễn một hệ thống lưu trữ với ba nodes:
- Node 1 gắn với tokens A và D
- Node 2 gắn với tokens C và E
- Node 3 gắn với token B
Note:
Các hệ thống quorum based thường sẽ sử dụng replication factor là số lẻ như 3, 5,...
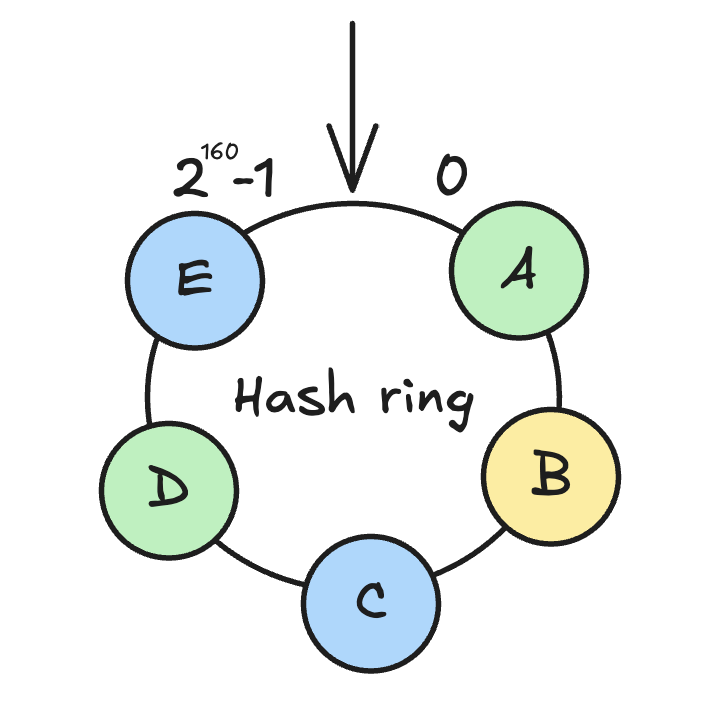
Hình 4: Virtual nodes
Như vậy, khi node 1 gặp vấn về và bị shutdown, dữ liệu của token A sẽ được chuyển sang B, của D được chuyển sang E giúp hệ thống được chia đều hơn thay vì dồn hết cho một node kế bên.